NoSQL Tutorial: CouchDB mit Java

Von: Kaveh Keshavarzi
Datum: 13.05.2011
Apache CouchDB
Zum Einsatz kommt die Dokumenten orientierte Datenbank CouchDB. Dokumenten orientierte Datenbanken sind eine spezielle Form von NoSQL Datenbanken, bei denen die Daten in Form von Dokumenten abgelegt werden. Das Apache CouchDB Projekt ist mit der Programmiersprache Erlang realisiert. Keine Angst! Um CouchDB nutzen zu können benötigt man keine Erlang Kenntnisse. Obwohl die funktionale Programmiersprache sicher mehr Aufmerksamkeit verdient hätte. CouchDB profitiert von der guten Unterstützung für nebenläufige, verteilte Systeme von Erlang. Angesprochen wird CouchDB über ein REST API, welches das JavaScript Object Notation Format verwendet. Das JSON Format wird auch für die Ablage der Daten verwendet. Weitere Besonderheiten von CouchDB werden im Tutorial beschrieben. Daher beginnen wir jetzt erst mal mit der Einrichtung von CouchDB.
Installation von CouchDB
CouchDB kann auf einer ganzen Reihe von Plattformen installiert werden. Neben Linux, Windows und Mac-OS wird auch Google’s Android unterstützt. Auf Windows war die Installation bisher nicht so einfach wie unter Linux. Seit neustem gibt es aber einen Windows Installer in der Beta Phase, den wir für das Tutorial verwenden. Das Tutorial kann natürlich auch unter anderen Betriebssystemen durchgeführt werden. Anleitungen für die Installation findet man hier.
CouchDB installieren
- Laden Sie den Windows Binary Installer 1.0.2 für CouchDB herunter
- Führen Sie Setup aus und folgen Sie den Anweisungen
- Wenn Sie CouchDB nicht als Service installiert haben, starten Sie CouchDB vom Startmenü aus
- Nach der Installation können Sie das Web-Interface der Datenbank (Futon) in Ihrem Browser aufrufen. Nutzen Sie dafür den Link in Ihrem Startmenü unter Programme/Apache CouchDB oder geben Sie http://locahost:15984/_utils/ in Ihren Browser ein – sofern Sie die Default-Einstellungen nicht geändert haben

Abbildung 1:
Datenbank einrichten
Der einfachste Weg CouchDB zu bedienen ist das Futon Web Interface. Abbildung 1 zeigt die Übersicht-Seite von Futon. Es bietet Ihnen die Möglichkeit neue Datenbanken zu erstellen, Daten abzufragen, Datenbanken zu sichern und vieles mehr. Alternativ können Sie jedes andere HTTP-fähige Werkzeug zu diesen Zwecken einsetzen. In diesem Artikel verwenden wir eine Kombination aus unserem Java Programm und Futon. Das Java Programm wird die Daten in die Datenbank eintragen und per Futon werden wir unsere Views für die Abfrage erstellen.
Damit wir von Java aus auf die Datenbank zugreifen können, muss diese erst mal existieren. Zum Anlegen einer neuen Datenbank gehen Sie wie folgt vor:
- Gehen Sie in Futon auf die Übersicht-Seite und klicken Sie auf „Create Database…“
- Geben Sie der Datenbank den Namen „filesdb“ und klicken Sie auf „Create“.
Demo-Projekt in Eclipse importieren
Um CouchDB von Java aufzurufen, gibt es mehrere API Bibliotheken. Diese benötigen wiederum weitere Bibliotheken.
Im Demo-Projekt sind diese vollständig beinhaltet, sodass der Code ohne weitere Einstellungen ausgeführt werden kann.
Im folgenden Projekt wurde die Schnittstelle jcouchdb wegen ihrer einfachen API eingesetzt. Andere APIs lassen sich ähnlich einbinden.
Zum Ausführen des Projektes gehen Sie wie folgt vor:
- Laden Sie das Projekt herunter und speichern Sie es in ein beliebiges Verzeichnis
- Importieren Sie das Archiv über File -> Import... -> General als ein existierendes Projekt in ihren Workspace
- Betrachten Sie die Java-Klasse predic8.couchdb.FileScanner.java in Listing 1
- Wählen Sie einen zu analysierenden Ordner aus. Per Default wird „c:“analysiert (Bei großen Ordnern kann der Prozess einige Minuten in Anspruch nehmen)
- Führen Sie das Programm aus
- Betrachten Sie das Ergebnis in Futon. Die Datenbank sollte nun wie in Abbildung 2 aussehen
package predic8.couchdb;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import org.jcouchdb.db.Database;
public class FileScanner {
/*
* Connecting to a database, using the
* server address and the name of the database.
* Note that the database have to be created before.
*/
Database db = new Database("localhost", "filesdb");
public static void main(String[] args) {
FileScanner fs = new FileScanner();
/*
* Choose the directory to be analyzed.
* It can take few minutes to analyze large directories.
*/
fs.processDir(new File("C:\\"));
}
void processDir(File f) {
if (f.isFile()) {
Map<String, Object> doc = new HashMap<String, Object>();
doc.put("name", f.getName());
doc.put("path", f.getAbsolutePath());
doc.put("size", f.length());
db.createDocument(doc);
} else {
File[] fileList = f.listFiles();
if (fileList == null) return;
for (int i = 0; i < fileList.length; i++) {
try {
processDir(fileList[i]);
} catch (Exception e) {
System.out.println(e);
}
}
}
}
}
Listing 1: Java Code des Programms
Das Ergebnis
Die Datenbank ist jetzt befüllt. Für jedes gefundene File wurde ein Dokument in der Datenbank erstellt. Jedes Dokument beinhaltet den Namen, den absoluten Pfad und die Größe der Datei. Abbildung 2 zeigt die erstellten Daten in Futon. In der ersten Spalte der Tabelle ist jeweils die eindeutige ID jedes Dokumentes dargestellt. Wenn beim Erzeugen der Daten keine ID übergeben wird, wählt CouchDB diese wie in unserem Beispiel automatisch. In der zweiten Spalte befinden sich Revisionsnummern, die ebenfalls von CouchDB automatisch erstellt wurden. Diese Werte dienen dem DBMS zur Versionierung der Daten. Damit wird die Konsistenz der Daten gewährleistet.
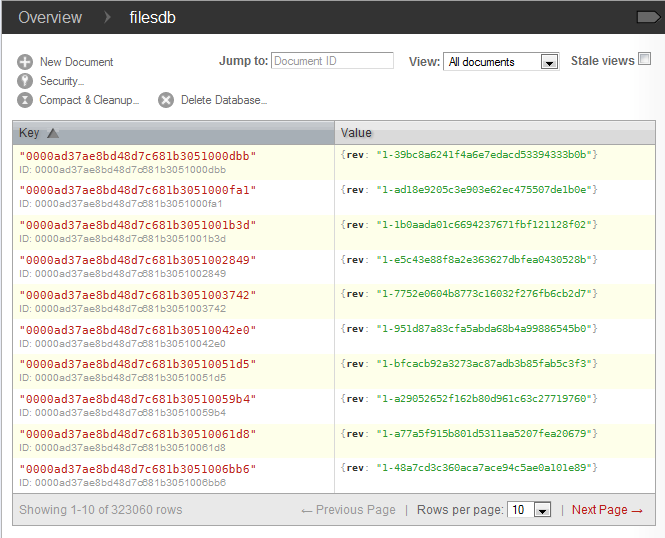
Abbildung 2:
Abfragen und Views
In CouchDB kann man mithilfe der sogenannten Map/Reduce Funktion neue Views erstellen, die die angeforderten Daten in Form von Tabellen darstellen. Zunächst wenden wir uns der Map Funktion zu. Die Map Funktion liefert als Ergebnis eine Tabelle mit zwei Spalten. In der ersten Spalte sind die Keys und in der zweiten die Values dargestellt. Die Tabelle wird automatisch nach den Keys sortiert.
Die Map Funktion
Betrachten Sie die Funktion: emit(key, value) in Listing 2
Der erste Parameter ist der Schlüssel „key“ und der zweite der zugehörige Wert.
Die Map Funktion wird für jedes Dokument in der Datenbank einmal aufgerufen.
So muss es im Gegensatz zu einer SQL-Abfrage nicht mehr angegeben werden, welche Bereiche der Datenbank betrachtet werden müssen.
Um die Anfrage dennoch einschränken zu können, werden Bedingungen in der Funktion definiert.
Hierfür sind alle Features von JavaScript gegeben. Für jedes Dokument der Datenbank,
das die Bedingungen erfüllt, wird ein Eintrag in der Ergebnistabelle erstellt.
Listing 2 zeigt die Map Funktion für unser Beispiel. Wechseln Sie zu Futon und wählen Sie in der Datenbank Ansicht von der oberen Leiste für „View“ die Option „Temporary View...“ aus. Tragen Sie die Map Funktion im linken Feld ein und führen Sie den Code mit einem Klick auf Run aus.
function(doc) {
var tmp = doc.name.split(".");
var ext = tmp[tmp.length -1]
if(ext.length < 3 || ext.length >4 ) return
emit(ext, doc.size);
}
Listing 2: Die Map Funktion
Abbildung 3 zeigt das Ergebnis der obigen Abfrage.
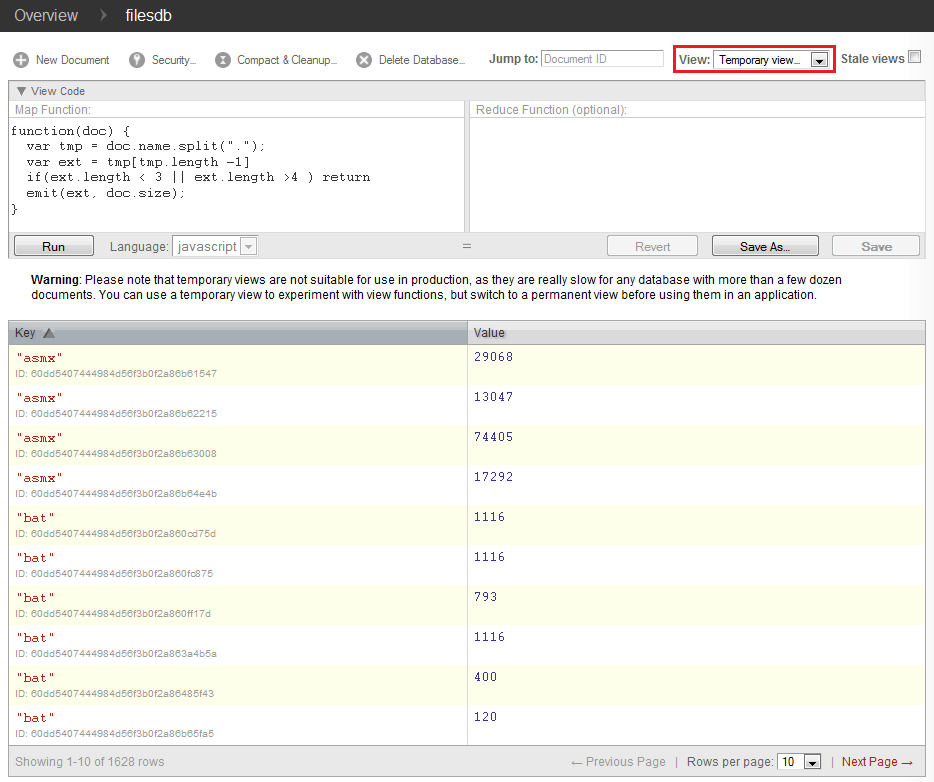
Abbildung 3:
Das Ergebnis ist wie erwartet eine Tabelle. Jede Zeile der Tabelle enthält einen Schlüssel (in Rot) und eine ID in der ersten Spalte und einen Wert in der zweiten Spalte. Die ID wird jeder Zeile automatisch hinzugefügt und dient der Erkennung des zu der Zeile zugehörigen Dokumentes (wie oben beschrieben, erhält jedes Dokument eine eindeutige ID). Die erste Zeile der Funktion spaltet den Dateinamen nach jedem Punktzeichen. Wir sind nur an Dateiendungen interessiert, die drei oder vier Zeichen lang sind. Diese werden dann als Schlüssel genommen. Als Wert wird in der zweiten Spalte die Größe der jeweiligen Datei dargestellt. Dieser Vorgang wird dann für jede eingetragene Datei ausgeführt und so kommen, wie in Abbildung 3 zu sehen ist, für jede Endung mehrere Einträge zustande. Wie kann man aber die Gesamtgröße eines bestimmten Datentyps herausfinden? Hier ist der Part, wo die Reduce Funktion ins Spiel kommt.
Die Reduce Funktion
Wie der Name schon verrät, erhält die Reduce Funktion als Eingabe die Ergebnisse der zugehörigen Map Funktion und gibt sie in einer reduzierten Form aus. Im diesem Beispiel summieren wir die Einträge mit dem gleichen Schlüssel auf, sodass für jede Datei-Endung die Summe der einzelnen Dateigrößen als Wert angezeigt wird.
function(key, values) {
return sum(values);
}
Listing 3: Die Reduece Funktion
Die Reduce Funktion bekommt zwei Parameter übergeben. Die Namen lassen vermuten wofür welcher Parameter steht. Aus den Einträgen mit dem gleichen „key“ wird ein einziger Hashmap Eintrag erzeugt. Der Wert dieses Eintrags wird in der zweiten Zeile der Funktion (Listing 3) berechnet.
In der Abbildung 4 sehen Sie das Ergebnis der Reduce Funktion. Somit steht in der zum Beispiel für den Schlüssel „doc“ der Wert „5066752“. Dieser Wert ist die Summe der Größen aller Dateien, deren Endung .doc gewesen ist. Um die neue Tabelle in Ihrer eigenen Datenbank sichtbar zu machen, tragen Sie den Code in die vorgesehene Stelle ein und setzen Sie das Häkchen in der oberen Leiste der Tabelle. Wenn dort noch kein Häkchen zu sehen ist, aktualisieren Sie die Seite in Ihrem Browser.
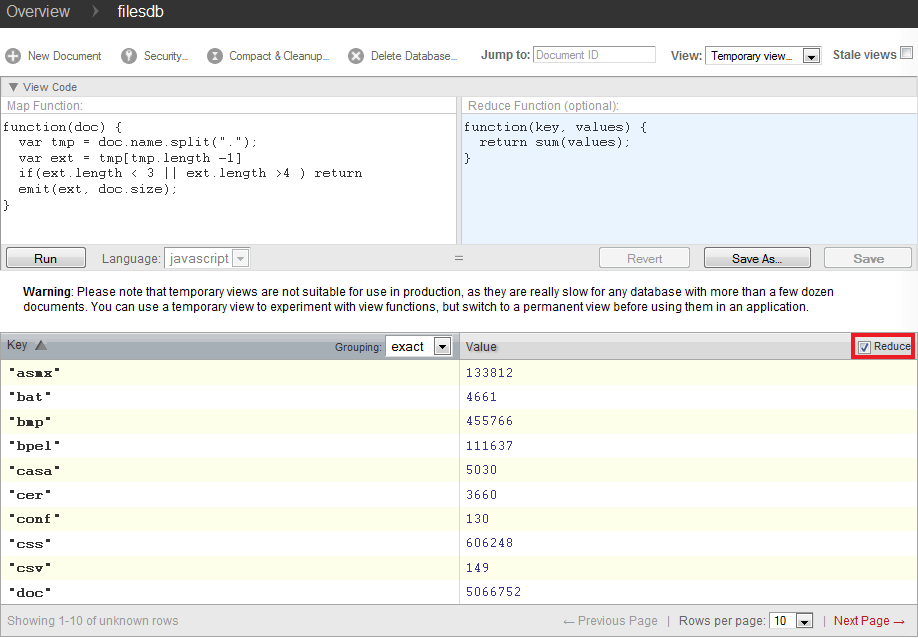
Abbildung 4:
Fazit
Es muss nicht immer eine SQL Datenbank sein. Für bestimmte Anwendungensfälle eignen sich NoSQL Datenbanken wie CouchDB, welche JavaScript und JSON verwendet.

